





















Day 2: Operating your AI data center with Juniper Networks

GPYOU: Day 2 – Operating Your AI DC
Juniper Networks presented its latest Apstra functionality for AI data center network operations at AI Infrastructure Field Day. It focused on providing operators with the context and tools to manage complex AI networks efficiently. Jeremy Wallace, a Data Center/IP Fabric Architect, emphasized the importance of context in understanding the network's expected behavior to identify and resolve issues quickly. Juniper is leveraging existing Apstra capabilities, augmented with new features such as compute agents deployable on NVIDIA servers, and enhanced probes and dashboards, to monitor AI networks. This presentation aims to equip operators to maintain optimal performance and minimize downtime in critical infrastructure environments.
The presentation highlighted the evolution of network management for AI data centers, transitioning from traditional methods to a more proactive and data-driven approach. The core of Juniper's solution involves leveraging telemetry, including data collected from GPU NICs and switches, to provide real-time insights into network performance. This enables operators to monitor key metrics, such as GPU network utilization and traffic patterns, and respond to potential issues swiftly. The Honeycomb view, traffic dashboards, and integration with congestion control mechanisms (ECN and PFC) demonstrate how to provide visibility into the network's behavior. The goal is to provide context and the tools to diagnose and resolve problems faster.
Finally, Wallace demonstrated a live demo of the platform, showcasing features like real-time traffic analysis, heatmaps of GPU utilization, and auto-tuning load balancing. The auto-tuning functionality dynamically adjusts parameters like inactivity intervals to optimize performance and eliminate out-of-sequence packets, increasing the likelihood of successful job completion. These power packs are essentially Python scripts and are evolving, with Juniper actively working on creating more of these power packs. Juniper is also working on deeper integration with other vendors for their customers' environments and solutions.
Presented by Jeremy Wallace, Data Center/IP Fabric Architect, Apstra Product Specialist Team, Juniper Networks. Recorded live in Santa Clara, California, on April 23, 2025, as part of AI Infrastructure Field Day.
You’ll learn
How Apstra Data Center Director assists with ongoing network operations
New features like compute agents deployable on NVIDIA servers and more
Who is this for?
Experience More





Transcript
0:00 i'm Jeremy Wallace and I work with Kyle i run what we call the product
0:05 specialist engineering team in Abstra and we just kind of we're like the Abstra janitors we do just about
0:12 everything so um I get to talk to you guys about taking all this stuff and now
0:17 running one of these networks with it right so we've seen a lot of the theory with the load balancing we've seen a lot
0:23 of the theory with how these AI data centers are built how they run k talked about standing them up and now I get to
0:30 talk about it from the perspective of the operator right what is if if I'm a if I'm sitting in a knock what am I
0:36 going to be looking at when I'm looking at these things so the thing the first thing that I want
0:43 to there there's a word that I like to get across your minds and it's the word context okay so when we build these
0:49 networks we have the full context of everything that should be happening
0:54 right so we know exactly the way that it's built and because we know the way that it's built we know exactly what
1:01 routes to expect in what locations we know exactly what interfaces should be where so this word context is critical
1:07 right so that's going to come up as a as a repeated theme the other thing that I
1:12 want to impress on your minds is this isn't necessarily new it's a new model of a network for the AI networks but
1:18 it's not new what we're doing we've been pulling this data out of the networks as Abstra for quite a while in different
1:26 kinds of formats whether it's an IP fabric or an EVPN vxline network the AI is just a new model right there's some
1:32 new data in there we got we've got some new agents that we can deploy out on these nick clust or the the GPU nicks to
1:40 pull data directly out of the servers there's a little bit of new things but what we're doing isn't actually new so
1:47 with that in mind these are some of the things that we're going to talk about right so if we're operating these
1:53 networks we know that any kind of an issue as in any other network is going
1:58 to be catastrophic we have a small glitch in a fabric or in a in a cluster
2:04 it's going to cause uh immense issues with the training jobs to be run or um
2:09 customer customer utilization whatever it is these issues are going to be catastrophic there's a ton of data
2:15 coming at us it's amazing how much data actually lives in the network in these
2:20 devices in the nicks there's a ton of data coming at us and and as operators I
2:26 remember my days as an operator trying to you know sift through the CLI and trying to find where the problems are right it's it's just an immense amount
2:32 of data coming at us all the time and then taking that data and digging down
2:37 and finding what is the actual problem where where am I congested where is my load balancing broken um those those
2:45 kinds of things so again it's all about the context we
2:51 used to take these networks and we'd stand up all these devices all over the place right so we have a whole bunch
2:57 of dots we have a whole bunch of devices and interfaces whatever it is sitting out there well if we can actually look
3:04 at it and say "This is a cat i now know how to in I now I now know how to
3:11 um my brain just uh interact with this cat right i know that if I go and I touch in this way it's not going to like
3:18 it but if I stroke it nicely we're going to have a happy cat networks are no different if we go and we push the wrong
3:24 configuration out we're going to have bad reactions we're going to have things go sideways we're going to have these these critical issues it's all about the
3:32 context if we have the context of what's actually supposed to be happening we can
3:37 pull out the right data and get to the root causes of the issues much
3:42 quicker all right so now with that in mind now that we're we know we're looking at a cat right we're looking at
3:48 this AI network we're going to look at some of the slides here and then I'm going to move from I'm going to move
3:54 through these pretty quickly i'm going to move into a live demo i like doing demos better than slides
3:59 this is just a representation of the body of the cat the body of the network right so this is a called the honeycomb
4:07 view and this shows all the GPUs that are available in the network we can break it down by different different
4:12 kinds of views so we have the view of the overall network all right we can dig down a little bit
4:19 deeper and we can get down into the pipes into the traffic dashboard so we can look at what's actually flowing
4:26 through the network we can see where uh where there's buffer utilization we can see where there's out of out of sequence
4:32 packets um congestion notification we can talk about that a little bit more in detail as well we can get down deeper
4:40 and pull this information out of the out of the networking devices and out of the GPU nicks
4:46 themselves we can see skip forward we can pull data out of the GPU nicks as
4:54 well we have like Kyle mentioned we have an agent that we deploy out on the deep on the GPU uh the GPU servers so now we
5:01 can pay attention directly to the nicks themselves and we can correlate that data with what's happening upstream in
5:07 the leaves and then from the leaves into the spines or you know across the rails however the the network is
5:14 built uh we can look at the congestion control stuff so we have and I I have a
5:19 I'll talk about this in just one second but there's different mechanisms for congestion control within an AI network
5:26 right when you're talking about Rocky and someone's might ask a question what does Rocky stand for RDMA which you know
5:34 remote direct memory access RDMA over converged Ethernet so it's just doing RDMA calls over our Ethernet network
5:41 within Rocky there's a bunch of congestion mechanisms to help us notify when when things are getting um bottle
5:49 bottlenecked and helping us to avoid that congestion and and provide back pressure to to slow things down so we
5:56 can go and we can actually configure these thresholds to to meet whatever
6:02 needs we have every workload is going to be a little bit different every network's going to be a little bit different every customer is going to
6:08 want to see slightly different thresholds and um drop at different levels that kind of stuff so we can we
6:16 can we can configure all those different uh thresholds and we can we can look at
6:22 look at it to say I want to create an anomaly if I have data that or if I have
6:28 um to if I have a certain number of drops over 10 minutes create an anomaly if I have one
6:36 drop in one second I might not care about that right or if I if my buffer
6:41 utilization gets to 90% for half a but drops back down that might not be a
6:47 problem but if it's at 90% for 10 minutes now we've got a problem so all of this is configurable to each
6:54 individual customer's needs and and training jobs and
7:03 networks with the the agent we can actually look at the health of the
7:09 servers themselves right so not only are we now looking at the CPUs on the switches and the memory on the switches
7:16 we're paying attention paying attention to the servers as well what's the CPU
7:21 utilization on the servers what's the RAM utilization on the servers right so that we can have all the way out to the
7:28 far reaches of of the environment and have it holistically um
7:35 monitored okay the goal for all of this stuff is
7:40 nothing more than keeping everything moving as fast as possible for as long as possible and the two mechanisms that
7:46 we have for that to help with that are congestion control so we have to make sure we can get cars on the freeway we can get the packets on the wire at the
7:54 appropriate time the appropriate speed make sure they're being delivered to the other end that's the congestion control
7:59 mechanism the other mechanism is the load balancing and they work hand in hand right so the load balancing make
8:05 sure all of our paths are utilized and then the congestion controls making sure the packets are going on at the right
8:11 time and all the stuff is working together to make sure no cars end up flying off the freeway inadvertently you
8:16 know that's when we start losing packets in a job things go sideways we start losing the effectiveness of our of our
8:24 uh of our expensive servers so the two me two of the
8:30 mechanisms that we use for and this is just a primer we're not going we're not going to go deep into the congestion
8:35 control the load balancing that's been discussed in other field days and in other sessions but I just want to give a
8:42 little bit of a refresher on what these are because we are going to see these in the in an upcoming demo here so the we
8:49 have two different mechanisms here the ECN's the um explicit congestion notification and the priority flow
8:55 control so the explicit the ECN's would be like you're on the freeway and it's
9:00 getting congested and now the brake lights start coming on going forward right and you're saying "Hey we might need to start slowing down a little
9:06 bit." And that's going to get to the end point and he's going to send back a congestion notification packet to the
9:13 beginning to the source and he's going to say "Pump the brakes a little bit you might need to you might want to slow down a little bit." Okay so that's good
9:20 ecn's are good that's that's indicating we're going to start behaving nicely with each other pfc's is like I'm coming
9:28 up on a traffic jam and I smash my brakes and everybody else behind me gets backed up right so now I'm telling everybody else behind me you got to slow
9:34 down but it's just it's a hard jam on the brakes okay so they're two different mechanisms so ideally we have more ECN's
9:41 in the network than we do PFC's question is there also a management view
9:47 specifically about PFC negotiation where I might be able to see PFC negotiation failures between switches or between my
9:53 endpoints um we can we can look at we can see
9:59 which device is initiating the PFC's backwards is that what you're is that what you're asking right is there
10:04 monitoring specifically yeah yes i'll show you a dashboard specifically for the PFC's being initiated we can see
10:11 exactly which device and which interface is initiating the PFC backward okay as
10:16 well as who's sending the ECN forward okay is the PC PFC that you're talking
10:22 about here is that part of the data center bridging is that the the same type of uh priority flow control that
10:28 was available through data center bridging yeah same kind of idea yes so this is this is Yes yes short version
10:35 yes okay yeah so I the way you were describing it it's typically you you do
10:41 that by assigning it to a particular VLAN and and you know that's the way
10:46 that you know which has priority so I wasn't sure how you could configure it other than just playing with the VLAN
10:52 yeah so this is we're actually going to see how this actually applies to a queue within the within the AI workload so
11:00 we're we're we're looking at this from the Rocky perspective and we can see a specific queue sending the PFC's back
11:06 upstream okay right so we don't have VLANs all through the network it's all layer three it's all BGP signal it's all
11:12 IP but it's all doing it back backwards um for the PFCs based on the the queue
11:18 and didn't mean to derail you just wanted to make sure that the definition hadn't changed on me
11:24 yeah okay so a year ago and I'm not going to redo this demo but a year ago
11:32 um we we presented a demonstration on what we called an autotuning DCQCM power
11:37 pack okay so DCQCN that's a crazy acronym data center quantized congestion
11:47 notification i think I got it right um it's just a fancy term for class of
11:52 service in advanced class of service in in the AI data center that's basically all it is so this autotuning power pack
11:59 what it the for DCQCN what it was doing is looking at the PFC's and the ECN's
12:07 and it would slide make move the sliding window for drop profiles left and right
12:12 right so the idea is I'm going to get as fast as I can and as close as I can to the edge of this cliff without jumping
12:19 off the edge of the cliff and dropping packets right so I'm going to back up a little bit and I'm going to move forward and get it exactly to where I need it to
12:26 be okay so this is this is a a tool looking at the APIs pulling data out of
12:32 the APIs looking at these PFCs looking at the ECN's and moving that sliding
12:39 window to get it exactly right so that the AI network is moving exactly where it needs to be
12:46 the reason I bring this up is because we're going to do I'm going to show a video of a of another demo similar to
12:52 this but it's another power pack that we've leveraged for load balancing
12:57 specifically so we talked about load balancing and you'll notice the one that's missing here is the
13:03 um the new the new one the RDMA based load balancing um excuse me
13:11 within these mechanisms of load balancing they kind of get more advanced as you go from you know kind of weave
13:17 through it and there's different places where you're going to use different versions of load balancing so the demo
13:22 that I have specifically shows the dynamic load balancing primarily because the network that it's built on is based
13:30 on Tomahawk 3 A6 which supports the DLB the Tomahawk 5 A6 supports the GLB right
13:38 so this when when we look at the difference between DLB and GB the DLB
13:44 like Vic was talking about we're paying attention to the quality of my local links right so it's a hop by hop
13:50 mechanism local links look on the spine my local links glb takes a whole bigger
13:55 picture right so I can look at the whole end to end what we're going to do in this demo when I get to that that demo
14:02 for the the DLB is we're going to see that we're paying attention to the entire network go back to that word
14:08 context we're paying attention to the entire network and doing almost the same kind of thing as GLB by looking at the
14:16 whole big picture and being able to move the different um settings the inactivity
14:23 intervals specifically to where we can have optimized load balancing and and
14:29 eliminate out of sequence packets right so that's I that's what I
14:34 just described here this is what we're going to see in the demo is this autotuning another autotuning mechanism
14:40 so if you have you have the autotuning for DCQCN running that's going to manage your congestion move that sliding window
14:47 then you have the autotuning for load balancing running and that's going to change that inactivity interval and as
14:53 those two things are moving together we're going to get that that network moving as close to the edge of the cliff
14:59 as possible and running as hot as it possibly can okay
15:05 any questions about any of that stuff so far great so with that I am going to
15:13 move into the Appstra UI here hopefully this works if I'm kind of angled a
15:19 little bit we got it mirrored so I'm I'm going to do a live demo and this is
15:25 running directly on our AI ML PAC lab that we have living in that building over there okay so this is this is real
15:33 hardware real GPUs real real switches um
15:39 nothing's nothing's virtualized here this is all this is all real stuff and I figured this is this is more interesting
15:45 than just kind of going through some theoretical stuff this is this is where I like to live we're going to try and jam some of
15:52 this stuff into like 15 20 minutes of demo and I recently spent four hours
15:58 with a with a customer going through this stuff because there's so much data coming at it so on that note one thing I
16:05 want to point out jump in here real quick one thing I
16:12 want to show is exactly how much data there is so if I come back over here and
16:17 I look at this this tab here this is this is a representation of our
16:26 cluster built on A100 um Nvidia A100
16:32 servers and it's a relatively small cluster it's going to be eight servers this is the this is the danger
16:39 with live demos it'll get there this is going to
16:44 it's going to it's built on eight servers with 16 leaves and eight GPUs
16:50 per per server so you can see it's it's a relatively small cluster right so there's 64 GPUs um it's all it's all railstripe
16:58 optimized so we each each one of these leaves is a rail if I zoom in here we can see that each one of them is a color
17:05 is that can you see that well enough so each one of these each each rail is identified by a color and each um each
17:13 one of these groups is a stripe so you can almost you can almost say a stripe
17:19 is like a pod almost all right it's just just kind of a loose analogy there so
17:25 this is what our network physically looks like we're talking about topologies this is what our network physically looks like now this is
17:31 something that I like to show just to identify how much there is to keep track of when I go into the graph explorer
17:39 this is looking at the actual graph database and we show the full blue the full blueprint
17:46 every one of these dots is something on the network and every l every line in here is a relationship that all this
17:52 stuff is a non-zero entity some you have to track it somewhere right either in
17:57 your brain in spreadsheets and multiple tools whatever it is this is where the context comes together these are all
18:03 these dots that make up that cat right we're not going to deep dive into the graph database just this is just kind of
18:10 a wow moment to say there's a lot of stuff to track in here right and those
18:15 have properties and stuff on them yes that's what makes it Yes so if I I can come in here and I can hover over this
18:21 and I can get contextual data out of every one of these dots
18:26 the UI for Abstra is nothing more than a first class citizen A API caller that
18:32 talks to the graph database that's it so everything in this graph database if a
18:38 if there's something that's not in the UI that a customer wants to do they can use uh whatever restful API tool they
18:44 want to use to create their own API calls directly into the graph and we have we have a number of customers that
18:50 do that themselves so and the relationships that can have properties as well yes yes yeah so so everything in
18:58 here has its properties and the the relationships will identify like this one is a link that goes between a leaf 4
19:07 and ixia i'm glad you can translate that yeah it's it's kind of it's hidden if I
19:12 click on that I think it'll stay up it's hidden right down in here so there you go it's pretty yeah I like it it's it's
19:20 cool and you know we can drag things around if I want to look at Ah here we go i want to look at this one and then I
19:26 can see where it links into right so we can play around with the graph database we can look at it the real power and
19:32 this is where I am not an expert we have other guys who are is you can go and you can create queries to pull the exact
19:40 data you want out of it then you can take that query throw it into an API call pretty cool all right that's enough
19:47 four hours to demo this thing how long does it take for somebody to learn to use this mhm
19:54 um it's actually easier than you would than you would think okay and you actually I'm not a graph query expert
20:02 myself and I almost never interact with the graph the graph is just there the
20:07 graph DB is just there picked a pretty thing so the CEO can show pretty pictures
20:13 this is what you spent your money on this is this is the secret room this is the secret sauce run yeah and in reality
20:22 it took Abstra a number of tries to get to the right kind of graph database to
20:28 make this work right so yeah it's it looks and and I like to bring this up
20:34 because this is what you have to keep track of right and it's difficult and if
20:41 you take this and you turn this into an EVPN
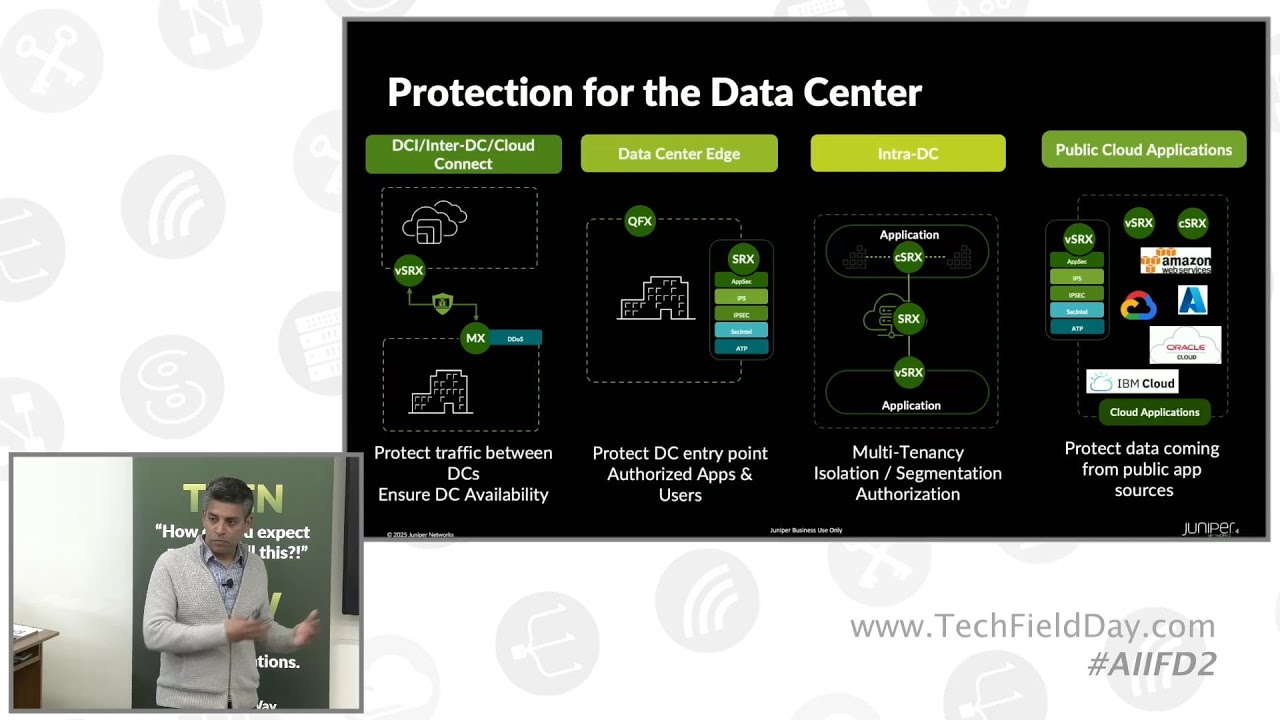
20:46 network gets even bigger okay so with that I want to step back and show this
20:54 so now here we have all these different networks that we're managing with a single instance of Abstra we have one
21:00 cluster that is based on EVPN right so this is where our H100's and our um AM
21:07 AMD MI300s live right now they're in this EVPN we're building multi-tenency
21:12 JVD uh Juniper validated designs based on EVPN VXLAN we've got the different um
21:20 o other backend fabric clusters so the the A100s that I'm going to be showing you are based in this cluster one we've
21:27 got a front-end fabric we've got a backend storage storage fabric all managed from the same instance we
21:34 understand the context of all these different networks and what's required in all these different
21:39 networks okay all right so when I go into my
21:45 cluster one dashboard here we're presented with what an operator would be looking at the operator would be sitting
21:51 there in his cubicle looking at pretty screens all the time right and ideally
21:58 and I'm going to come back to these probes here i'm not I'm not glossing over that ideally when he's in here looking at this this is what it looks
22:05 like because we have the reference design the best practices we push out
22:10 the correct um configurations and one story that I actually like is one customer called us
22:16 up one time they're like "Why do I do this this i never see anything red anymore i don't have any problems." And
22:22 I was like "Well that's because we pushed out the correct," and this was an EVPN customer this is some years back
22:28 this is an EVPN customer that's because we push out the best practices that you need for your environment they're like
22:36 Ah got it. So that that's a real story by the way that was I I talked to that
22:41 customer personally but this is ideally what you see and we have representations of our BGP connections our cabling this
22:49 is what Kyle talked about the cabling map if we have if someone goes in and and replaces a server and puts a cable
22:55 in the wrong switches the ports we'll we'll tell you that hey these cables are switched they're reversed um there's
23:02 ways we can automatically remediate that or we can tell them "No go physically remove it or we can just use an LLDP
23:08 discovery and pull that back in and fix it dynamically." So there's different this this
23:13 this is what we want to see all healthy all green
23:20 right user before I jump into the probes this is the interesting part and I can
23:25 tell you that something is now broken on our Ixia because I've been playing with this enough but this is the honeycomb
23:32 view and I showed you a screenshot of that a little bit ago this represents
23:37 every GPU in the fabric and I can take this and I can group it in in different
23:43 groupings so if I want to look and see what each one of my physical servers itself is doing this is now her server i
23:50 can do that if I want to see what my rails are doing I can look at each rail and I can see that I've got some rails
23:55 misbehaving i'm going to explain these colors here too this is a heat map of our GPUs it's
24:03 not a status indicator so if you think of a heat map the hotter it is the redder it is the better it is this
24:11 indicates how hot our GPUs are actually running ideally we want them all to be
24:16 running at this um this brown like 81% and higher right the the closer we can
24:22 get to 100% the better we're going to be the the the better our training model is going to run the quicker the job
24:28 completion time is going to be i happen to know that the Ixia is broken right now because this is the exact traffic
24:34 pattern that we saw when the Ixia broke couple days ago so the Ixia is doing
24:39 something weird we're sending a bunch of traffic with the Ixia creating a bunch of congestion i'm going to show you where the out of sequence packets are
24:46 and stuff like that so but what this indicates and this is actually cool i actually like this because now that if
24:52 I'm an operator I can look at this and go "Ah crap i've got some of my GPUs are
24:58 not operating at their peak efficiency what's going on?" Um right now I'm sorted by rails i
25:05 can take this and sort it by servers and I can select a specific server i can see
25:12 these if I zoom in here um and each one of these GPU 0 GPU one that is a rail so
25:19 zero rail zero rail one rail two i can see that rail one and rail three there's
25:25 something broken there now I can tell you that rail one happens to be a switch
25:31 that all the Ixia ports are coming in on and rail three is the other switch where all the Ixia ports are coming in on so
25:37 it makes sense that Ixie is dumping traffic in there creating a lot of back pressure a lot of congestion and that's
25:43 sending it back to the the servers okay but if I'm an operator I
25:49 can look at that and go dang you know what's going on here so when I come up and I look at my
25:56 probes this is going to give me an example of what's going on
26:03 in the network and this is going to tell me there's going to be a whole bunch of out of sequence packets and a whole
26:08 bunch of uh ECN frames and um things like that going on quick quick question
26:14 about how you're getting that data i'm assuming it's some sort of telemetry subscription and you're just getting the telemetry off the ASIC for that correct
26:21 correct there's a combination of RPC calls out to an agent so that's actually
26:26 a great question and I'll take a step back and explain that in Abstra we have the Abstra here we go this is the danger
26:33 of real demos there we
26:40 go okay in in Appstster we have the Abstra core server and then there's
26:45 agents that live out in in either on the devices themselves or that's an onbox
26:51 agent or we have an off-box agent that sits as in a small Docker container with the Abstra server the ideal is to get
26:58 them on the onbox out to the devices so we're we have and then we have a either an RPC call that will go out and pull
27:05 data it's not SNMP just an RPC call right or we'll do gRPC streaming data
27:11 back in on some some of the some of the counters all right there we go okay so here we we
27:19 have a whole bunch of out of sequence stuff and we can look at this and see here's a system ID and we'll correlate
27:26 this a little bit easier here in just one second because when I look at a serial number that doesn't mean much to me but I can see that on GPU3 E I've got
27:34 a whole bunch of out of sequence packets coming in out of sequence packets is indicative again of core load balancing
27:41 somewhere right I've also got CNPs going on and the CN MPs is indicative of
27:48 congestion so I've got something going on within my network where I've got both out of sequence packets and I've got
27:54 CMPs so I've got bad load balancing and bad congestion happening you know it's the Ixie is doing all kinds of crazy
28:01 stuff to to make this a mess so if I go back over here to my dashboard just
28:06 going to scroll down and show some of the parameters that we then that an operator would go and look at as he is
28:13 trying to figure out what's going on so we can create we can pull this data
28:19 out of the network and some of these graphs are based on 7-day intervals some of them are based on one hour
28:26 intervals and a user can go and create these graphs based on what they want to see the intervals they want to report
28:33 back up to their VPs right hey over the past seven days we've had this this much bandwidth in our AI network kind of a
28:39 thing so as we scroll down and look through this I'm just going to show you some of these graphs that we've created
28:45 really quickly um we've got spine spine traffic and if you hover over these you
28:50 can actually see the the amount of not supposed to leave the white line you can
28:56 see the amount of bandwidth on on each interface on the spine right so one of them is operating at like 400 gigabits
29:02 per second that's that's cool that's good that's what we want um and same thing you can go down and here's here's
29:08 our leaves our leaves for stripe one and our stripe two leaf so we can we have this broken out now per stripe we're
29:15 getting just a little bit more granular as we keep scrolling down through here we can look at total traffic over the
29:22 last seven days so you can you've got bandwidth u this you know here's here's
29:28 where gaps where the job stopped running ideally it's all just running really hot
29:33 right and when we look at this if you look at the the value it's 4.95 terab
29:39 right now if I come down I get a little bit more granular now I'm going to look at my intrastripe so stuff within my
29:47 stripe this is 3.1 terabytes and if I go
29:55 interstip between my stripes now we have the uh 1.76 terb so
30:02 now we take that 1.76 and the three you know and that adds up to the total traffic right so we can keep getting a
30:08 little bit more granular as we keep moving and these these dashboards can be swizzled and moved around however
30:14 however an operator wants to see it yes hi Denise Donahghue can you set it
30:20 up to notify you proactively when things start creeping yes yes there are there
30:26 are different ways to to set that up um yeah in fact in the in the demo that
30:33 we did last year with the congestion notification they actually had that set up with Service Now to where the
30:40 congestion notification would pop up and Service Now would open a ticket so the users would get that scrolling right
30:47 through Service Now and as things changed in service in the in the network the ticket in Service Now would change
30:52 and when the congestion got relieved or got completely fixed the ticket would get closed in service now
30:59 do you provide any integration with the other third party uh observability
31:05 stacks or monitoring um the the the we don't necessarily
31:12 provide that D or from from juniper ourselves but that's all available with
31:17 the rest APIs so there are other customers doing things with other kinds of observability platforms yes we do
31:24 have a telegraph plugin yeah that we can use and we work with Graphfana a ton so
31:30 that that's all there and then and and of course we have the the flow where we
31:36 can get lots of flow stuff and all that can go to different places so yes okay gotcha
31:43 other questions okay yeah maybe a question um I'm looking further as well
31:49 to miss one is there also because notifications is always a good thing if there's a problem but wouldn't it be
31:56 better that there's also a recommendation engine saying that hey there is a problem and we advise you to
32:02 do this or that yes so yes push the button and it happens yeah so with the with the cloud
32:10 services with the mist piece yes um that that is going to be more part of that
32:15 where you have a a a the um AI ops engine running up in the
32:22 in mist and we'll be able to have different kinds of things you can visualize in there we can already do
32:29 that with the EVP and VxLand stuff where you can you can look at a service and you can see traffic flows through the
32:36 network with a service you can see what would happen if I it's called a failure analysis what happens if I create a
32:42 break here you can do things like that and it will create or it can it can create recommendations but so that's
32:48 another UI that I need to use then so it's not in here yet correct that's not part of Abstra okay that that would be a
32:55 different window that would be running and you can launch Abstra from ACS oh
33:01 okay so you can you can click on it'll say this instance of Abstra is is reporting this issue click here to go do
33:07 this thing okay thanks yes jim Sprinsky
33:12 CDC the whole concept of a rail I'm still trying to get my head around that and is there what to elucidate on that
33:20 is there a specific thing you would monitor a rail for instead of some of the other things here yeah so let me
33:28 just jump back over here so I'll show you I'll show you a
33:34 comparison of what it looks like with a rail versus a non-rail okay so think of
33:39 let me just zoom this in a little bit better so we can get a little closer okay so if
33:46 you if you look at these you can see that you I have I've got four purple links and four blue links right gotcha
33:52 so a rail is nothing more than every server has eight nicks gotcha i've got
33:59 eight leaves ah nick zero goes to leaf zero nick one
34:04 goes to leaf one got it so rail zero is everything going to that one leaf got it
34:10 okay that makes sense that's somewhat simplified you can you can do it where if I have a leaf maybe I have two links
34:16 in a rail you know so there's different things you can do there but that's kind of the idea behind it is the nicks map
34:22 to the same place okay and so would there be a there's obviously specific
34:27 metrics that you're watching there and if you saw a failure on a rail that
34:34 would indicate what typically that something's wrong at the in at the
34:39 server at the nick or it depends on it depends on I mean the failure is going
34:44 to be wherever the failure is right I see kind of kind of a dumb statement but
34:49 if and I don't see that necessarily too terribly different from any other network if I've got so let me show you
34:55 what I mean by that real fast please if I can zoom this out I'm just going to
35:00 close that window there okay let's go back over here to um our blueprints so
35:06 if I look at this particular instance the the EVPN instance this is where like
35:12 I said where the H100's and the MI300 the AMD A6R if we look at this one this
35:18 is our multi-tenant so this would be like your GPU as a service cluster okay Right inside here you'll see that this
35:24 one is not built necessarily in a rail and stripe fashion okay but if I have a
35:29 GPU failure in a rail it's still a GPU failure if I have a an interface failure
35:36 I'm I'm just going to get it reported in a in different language so it'll say um
35:41 stripe one rail one interface et000 got had a failure okay versus here it's
35:48 going to say it's just a classification essentially exactly okay we're still working with Rocky between the GPUs
35:55 right so we're still looking at the the F the PFC's backwards ECN's forward CNPs
36:01 we're still looking at those same kinds of things okay it's just the terminology is going to change a little bit so just the topology term is really what it
36:07 comes down to yeah got it and one and one thing that we are actually working towards it's not in appstream yet but
36:14 we're working towards is having rail optimized and evpn together
36:21 okay okay so now imagine that one okay uh-huh that's not the system blowing up
36:27 that's like my mind just blowing i I work with this stuff every day and I'm still blown away by the
36:34 things that we're moving forward this the speeds we operate at um I actually loved our hashtag and this this kind of
36:41 goes along with what we do with Abstra i love the ha the the tag we used to use engineering simplicity
36:48 uhhuh get it get it this stuff is not simple
36:54 so we we tried to take and and there was a guy that I used to work for and I we were in a meeting with a bunch of people
37:00 talking about APIs and all this stuff and he just stopped the meeting prophet might remember this he stopped the
37:07 meeting and he goes "Hold on nobody cares about this piece under the iceberg
37:13 what's the very shiny tip that our users are going to interact with?" Right this is Abstra up here there's a whole bunch
37:20 going on underneath here this is the important part this is what we interact with that's how we interact with all
37:26 these other right you know think about the cat right we interact with the eyes we fur we don't we're not touching the
37:34 intestines and the heart but we know it's there and we know it's important we got to keep it healthy we've all had the
37:40 experience of a user that we really respect walk up and go "It's running slow we get it." Yeah exactly and so so
37:48 so back to this as we as we get a little deeper down it's running slow right that
37:53 that is a it's such a common theme that we don't know it's slow until 3 days
38:00 later right and someone comes to us and says "Hey my job ran slow three days ago
38:07 right over the weekend." The cool thing one of the cool things about Abster is we can do all this stuff in a time
38:13 series database we can keep all this data and I can take and I can run a dragging slider back and forth it's
38:21 actually something that I'll that's I think it's kind of cool i'll show you real fast here um if I go to the the
38:26 active tab here and we look at this heat map
38:36 um so with this traffic heat I can turn this into a time series and I don't this
38:41 is on the this is on the EVPN cluster so I'm not actually sure what's there but I can take and I can drag this back and
38:47 forth and I can show and they can say "Hey Saturday morning at 2 a.m there's a
38:54 noticeable slowdown and we can go and look at the network and it will show us exactly where congestion happened where
39:01 bottlenecks happened right that that kind of a thing so it was probably a DNS failure yeah it's always it's always DNS
39:09 right yeah it's always DNS now uh because it holds a lot of data um and it
39:16 collects it from all those devices um and so on and interfaces where does it
39:22 store the data it's got to be a really big database is it in that AppScra server is it somewhere else in the cloud
39:28 or a combination of how long do you keep that data that's a great question so on
39:33 on the Abstra server we keep 30 days worth of data uh if you want to keep a
39:39 year or two years or more worth of data then you export it out to something like Graphana Telegraph or up into the cloud
39:47 services and we can keep the data longer in in the cloud on the server itself in
39:52 order to keep it from becoming like terabytes in size we just keep 30 days
39:58 worth of data because it's a VM right correct it's a VM okay correct
40:03 yep so that's 30 days of completely non-aggregated or compressed data correct granularity yep that's all the
40:10 raw data that we pull from all the agents all the RPC calls everything that's coming into us we keep that for
40:15 30 days yeah okay in the interest of time I'm
40:21 going to jump over to this um autotuning load balancing demo and I'm just going
40:27 to start this and this is playing at 2x speed so this is it's sped up a little
40:32 bit and you're going to see what's what what's happening here is initially the inactivity interval timer was set for 64
40:40 right and so it's set really really small and when it's set really really small we're going to start seeing a lot
40:46 of out of sequence packets and as as we're monitoring the network for these out of sequence packets we're going to
40:53 start backing that number up to get to where we eliminate completely the out of sequence packets
41:00 um the way to think of the inner the inactivity interval in
41:06 um in DLB I I I like to think of it as like the professor timeout interval
41:13 right we've all been there with college or high school when you walk into the class and you're like "How long do I have to wait for the professor?" Right
41:20 how long and and if you wait for 30 seconds and you bail out that's too quick you might you're probably going to
41:26 miss something you're going to miss a professor something important is going to happen if you wait for too long and you sit there for 3 hours well now um
41:34 you know who knows what's changed in the world of the news in the past 3 hours and all you you miss all kinds of errors
17:39 and all kinds of things happen the inactivity interval isn't really any different than that if it's set too
17:45 small I'm going to create my own problems there's there's going to be uh out of sequence frames i'm going to
17:51 receive things on the wired incorrectly if it's set too big I'm going to miss the opportunity to detect the actual
17:59 problems on the network right so this is the whole purpose of this is to monitor the network
18:05 continuously and then make incremental changes this is like I'm touching the
18:10 whole cat now right so I'm looking at the whole cat and saying "Okay there's there's a little piece here that's
18:17 unhealthy let's holistically heal the cat." Um kind of a thing so I'm just
18:23 going to speed this up a little bit you'll see right now where we've got the um the it's the out of sequence packets
18:30 is at 1675 there's a value up there if I click forward a little bit here in time
18:36 the value is now dropped down to six out of sequence packets it might jump up back up as as the timer is going back
18:43 and forth and the idea with this autotuning mechanism is to get this down
18:48 to where it is actually down to zero out of sequence
18:53 packets and now we have an ideal inactivity interval for this specific
19:00 job the goal here is not necessarily to be faster than every algorithm in the
19:06 world or every every computer in the world the goal is to be faster than humans right if if we're sitting there
19:13 looking at this and I'm waiting for an out of sequence packet I now have to go and touch every device I have to figure
19:18 out where it's coming from the goal is to be faster than humans so if if we
19:25 start a job and this job is going to run for three hours or it's going to run for three weeks or three months whatever the
19:30 job's going to run for however big it is if I can resolve some of these things
19:36 the congestion or I can resolve the load balancing within the first couple minutes of that job running I
19:42 dramatically increase the odds of my success of the job brain to completion in a time that I want it to run right
19:50 so that's the that's the idea behind these autotuning things and one of the
19:56 cool things that we can do with Abstra is and this is something that we're work
20:01 actively working on within my team is building more of these power packs as we're calling them
20:08 that we can move features to AppStra just a little bit quicker right and then
20:14 we look at them we say "Okay this is a good one let's pull this and actually pull this into the product."
20:20 And the power packs are just Python scripts this one's a Python script yep and the the congestion map notification
20:26 is a Python script as well yep how often are you seeing like rate of change in
20:33 this particular perspective and and what I mean by that is how often am I am I reconfiguring the cluster enough to have
20:41 additional problems created for myself are you saying this is more of an enterprise perspective where I maybe
20:46 have a cluster that I don't mess with very often um what would you say is like the give and take on rate of change and
20:52 how often I'm redesigning a cluster that's a good question um it's probably something we'd have to take more and
20:59 discuss a little bit more offline i don't have I don't have really have good data behind that necessarily um ideally
21:06 not very often right you know ideally you get it to where the you you solve
21:12 the problem with a few configuration changes at the beginning maybe it's just with an inactivity interval timer mhm
21:18 ideally you're not touching it a whole lot you know so I've built it day 0 day
45:23 1 day two right and I'm running it yep i'm just kind of doing a a reactive monitoring at that point right because
45:29 I'm not rebuilding my cluster very often so I have to imagine it gets into a stable state pretty quick right correct
45:36 that's the idea now the the place where I could see it changing is maybe I run job type A and it has certain size of
45:43 packets and certain inter um inactivity interval right or the the congestion
45:52 notification pieces are have a certain place in that sliding window job B it
45:58 slides a little bit to the right here and the inactivity interval slides a little bit down here you know so having
46:04 those things running constantly I may have to make a configuration change here depending on the job that's
46:11 going to change right could potentially yeah okay yeah the idea is that every customer is going to be a little bit
46:17 unique just like every cat's going to be a little bit unique you're going to have a little bit different requirements for food this one's going to make him sick
46:23 this one's not so changing those things when needed as early as possible and
46:28 then having it just set stable is the idea yeah