





















Maximize AI Cluster Performance using Juniper Self-Optimizing Ethernet with Juniper Networks

Maximize AI Cluster Performance with Juniper Self-Optimizing Ethernet
Vikram Singh, Sr. Product Manager, AI Data Center Solutions at Juniper Networks, discussed maximizing AI cluster performance using Juniper's self-optimizing Ethernet fabric. As AI workloads scale, high GPU utilization and minimized congestion are critical to maximizing performance and ROI. Juniper’s advanced load balancing innovations deliver a self-optimizing Ethernet fabric that dynamically adapts to congestion and keeps AI clusters running at peak efficiency.
The presentation addressed the unique challenges posed by AI/ML traffic, which is primarily UDP-based with low entropy, bursty flows, and the synchronous compute nature of data parallelism, where GPUs must synchronize gradients after each iteration. This synchronization makes job completion time a key metric, as delays in a single flow can idle many GPUs. Traditional Ethernet, designed for TCP in-order delivery requirements, doesn't efficiently handle this type of traffic, leading to congestion and performance degradation. Solutions like packet spraying using specialized NICs or distributed scheduled fabrics are expensive and proprietary.
Juniper offers an open, standards-based approach using Ethernet, called AI load balancing, which includes dynamic load balancing (DLB) that enhances static ECMP by tracking link utilization and buffer pressure at microsecond granularity to make informed forwarding decisions. DLB operates in flowlet mode (breaking flows into subflows based on configurable pauses) or packet mode (packet spraying). Global Load Balancing (GLB) enhances DLB by exchanging link quality data between leaves and spines, enabling leaves to make more informed decisions and avoid congested paths. Juniper's RDMA-aware load balancing (RLB) uses deterministic routing by assigning IP addresses to subflows, eliminating randomness and ensuring consistent high performance, in-order delivery, and non-rail performance without expensive hardware.
Presented by Vikram Singh, Sr. Product Manager, AI Data Center Solutions, Juniper Networks. Recorded live in Santa Clara, California, on April 23, 2025, as part of AI Infrastructure Field Day.
You’ll learn
The latest load-balancing techniques for AI workloads
How to run your AI cluster at peak efficiency with self-optimizing Ethernet
Who is this for?
Host
Experience More





Transcript
0:00 in the AI data center solutions reporter Proful today I'm going to talk about how
0:05 to maximize you know AI um cluster performance using Juniper's uh self
0:11 optimizing networks so um I know earlier you had
0:17 asked like how you know can you show a topology so let's look at like you know what are the challenges how AI
0:23 application traffic is differs from traditional data center right so uh most
0:29 of this uh rocky is over UDP and also what happens is uh there is very low
0:35 entropy so there are very few flows they're busty flows high bandwidth and
0:40 uh some of them live throughout the training right so that's the first challenge in the property of the flow
0:47 and the second one is if you see training when you parallelize it over multiple GPUs hundreds of GPUs um one
0:55 kind of parallelism is data parallelism which is very popular in that case GPUs are lock step so they all load their
1:03 batch of data that they are going to train on and at the end end of that iteration they have different gradients
1:09 that they have to synchronize amongst each other and until they do that um you
1:14 know they cannot move to the next batch so they're kind of idle so that's why there is that synchronous compute um
1:21 during training that uh you know even exacerbates this this problem so a single flow that is delayed in this
1:29 synchronization could really you know keep a lot of GPUs idle so that's why
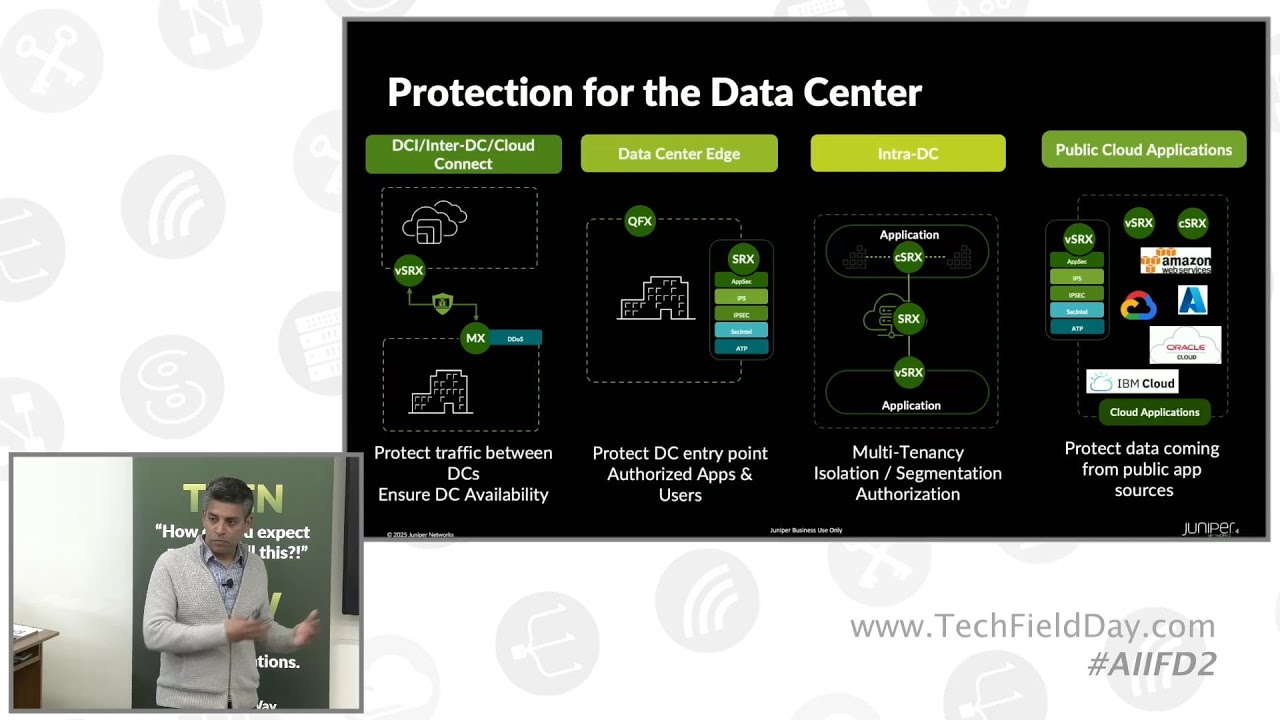
1:34 job completion time is a is a key metric now in this diagram above what you see is it's a physical topology strategy
1:42 that you say hey uh I can ease the burden of my load balancing so this is Nvidia has been prescribing this u and
1:49 it's called rail optimized um so the first uh nick of every so every GPU has
1:54 its own nick and the first nick or first GPUs are connected to the same switch um
1:59 so there are eight GPUs in the DGX form factor or similar and you see eight
2:04 switches or eight rails being created and then uh you have the spine layer in
2:10 the leaf to spine there is one is to1 or subscription to just handle this capacity um as and these are uh physical
2:16 topology uh strategies that will give you the best chance on on you know to keep the performance
2:23 up now uh Proful alluded to this and and and he said he he he he mentioned that
2:29 okay traditional in the traditional um or Ethernet or what we call static ECMP
2:35 that catered primarily to most non-AI applications that were built on TCP and TCP said hey just give me uh in order
2:43 packets uh delivery right and that was because you know TCP has this exponential back off whenever you know
2:49 packets are out of order and also it has a slow start so the bandwidth hit whenever whenever that happens is pretty
2:55 uh bad uh whereas in Rocky's case there is no slow start there is uh you know
3:00 all these flows are always busty they come in uh you know and are long lived so the the traditional Ethernet which
3:07 was like do a hash and pin a flow for its life cycle on a path which was TCP's main ask um worked well in that space
3:15 because there was so many flows there were enough entropy some long live shortlived so a natural distribution or
3:21 a random distribution worked well in this case if you apply that you can get in uh even if you have one is to one or
3:27 subscription you will get in uh trouble where you know u you can make forwarding
3:32 decision or load balancing decisions uh at the leaf and overs subscribe a a a a
3:37 leaf to spine link or two leaves independently sending traffic could overload a spinetoleaf link so really
3:45 what we need is more efficient load balancing that is designed for handling rocky
3:51 traffic and again uh Proful mentioned this that congestion is uh can really
3:57 bring down um you know the performance of these AI workloads again because a single flow can delay can cause um cause
4:04 that and so that's why avoiding um that congestion because you have enough
4:10 capacity is the key strategy uh for maximizing performance performance now if you see here like
4:19 I've just set up currently and there was a discussion in the previous session as well like uh if you see packet spring
4:25 appears to be the uh you know current um best method of load balancing and there
4:32 is truth to it so if you see smart based solutions where you know these flows hit the first leaf um and then you know
4:38 packets are spread across um all the ECMP paths and then they are delivered
4:44 out of order to the nick so you need specialized nicks or super nicks today uh which can basically handle those out
4:51 of order packets and the other thing is you know the other approach is distributed schedule fabric where same
4:57 thing flows hit the first leaf then they are sprayed over just like you do it in a chassis based uh fabric solution
5:04 there's a credit grants based mechanism and then packets are basically sprayed to load balance across spine but in this
5:11 case some of them chop it into cells some don't and they would reorder at the
5:17 uh reorder these packets because again spraying is is is uh you know uh will cause out of order but they will reorder
5:24 the packets before they ship it to the GPU nick so in this case they of course you
5:29 need deep buffers uh to enable that and if you compare
5:34 um you know the cost is is is again both of these solutions are expensive the super nick ones now you need specialized
5:41 nicks which are more expensive to begin with but are also more expensive in terms of they they consume more power um
5:47 and you know already these GPU uh servers or racks are power constrained now you're adding almost 400 watt more
5:54 power to each server uh using this And on the second one yes of course um these
6:00 leaves are debuffer and there hence they are more expensive um uh you know uh and
6:06 also both of them are proprietary so you are logged in in a in in a uh on the
6:12 left hand side you will be using vendor A's proprietary nick to achieve this and
6:17 uh you know uh so you'll be logged into any expansion of your AI data center because you know because of that and
6:24 also in the case of the distributed schedule fabric you are definitely logged into that uh the whole uh fabric
6:30 ecosystem there from a single vendor so now let's look at um Proful
6:36 mentioned this in the previous session but I'm going to go dive it a little bit deeper that how Juniper's open and
6:41 standardsbased approach uh using Ethernet u solves some of these problems
6:46 um and the umbrella we are calling it AI load balancing so the first technique is
6:52 dynamic load balancing right so this is an evolution or enhancement over static ECMP where we take more informed
6:58 decision instead of just doing a hash and randomly pinning a flow on all of on one of the available paths we track uh
7:06 almost at a very every microscond granularity that hey what is the link utilization or what is my link quality
7:13 um uh at at every leaf where the first uh these this traffic hits right so as
7:20 you can see the most opportune point where you can take a good load balancing decision and avoid congestion is the
7:27 first leaf because it has the most available paths so what we do is we track link quality which is a function
7:33 of how much traffic is going so link utilization on every link we track that
7:38 and also see that hey is there any buffer pressure on any of those links so those two metrics are combined and we
7:45 derive um link quality and here I'm just showing for simplicity three three bands
7:51 um uh but there are actually eight bands of link quality so we classify every link from a 0 to 7 and when actually
7:59 these flows come in real time at that instance of time every at a microcond
8:05 granularity we say hey which is the best link based on this link quality
8:10 available and we start placing the the the flows there hey D um who's making
8:17 that decision the switches the leaves themselves yes so the this is all in the
8:23 um in the ASIC logic so this is done real time at line rate yes
8:28 so to follow up on that is to what Denise is asking there where's the state being managed right i'm monitoring the
8:35 flows i'm I'm holding on to that information is that some sort of packet broker or docker container running on
8:41 the leaf or the spine what's what's handling that or managing all that flow yeah so this is none of that this had
8:47 because these 800 gig so the this is like let's say our current generation is 52 uh sorry um uh uh 64 by 800 gig and
8:55 when all of them blow up you have no time to you know so this is all burned in the logic in the ASIC itself so these
9:01 decisions um along with our Juno software is actually a function of of that so that's why it's able to it's a
9:07 non-blocking switch it can if all 800 gig 64 ports blow up this can do all this at line rate for all of those
9:15 um and that's the only way because you know otherwise you'll introduce delays and and you can get in trouble so um so
9:23 there are certain um so two primary methods on how you do this right so as I
9:28 said there are these flows are long lived and very few of them so to extract
9:33 more entropy the first one is flowlet mode right now what the flow flowlet
9:40 mode does is extracts more more flows or subflows in time right so if a flow
9:45 pauses for a configurable amount of time and the next bust comes in we can treat
9:51 it as a new flow even though it's like the fi same five tpple right uh in in the traditional Ethernet so that way we
9:58 can break these uh flows into more uh subflows and then start uh you know fairly uh distributing them uh based on
10:07 that instance of time whatever was happening and um this works very well for AI workloads because you know in AI
10:15 workloads there is this natural tendency of compute and synchronize so all the
10:20 GPUs that are participating let's say in all redu they will take their load their batch of data and as I said their lock
10:27 step once they're done with their computation they'll synchronize so there is a natural pause and that fits very
10:32 well in this and this doesn't introduce any out of order packets because you know the previous burst of or a previous
10:39 flowlet in this case we if we put it placed it on a path let's say to spine
10:44 one and the next burst we after waiting let's say 20 microsconds or 16
10:50 microsconds we place it on a on a better path at that instance of time the previous packets would have reached the
10:56 destination that's the assumption that's why you don't see uh you shouldn't and see out of order packets now the second
11:02 mode is packet mode as the name suggests you can see we make this decision on a per packet basis so this is the
11:10 classical packet spraying so we will spray the packet uh across these uh ECMP paths we will still factor link quality
11:17 in it so if some link still gets degraded um you know we will avoid that link even praying u but this is um this
11:25 is packet request quick question sorry um because now you say every switch will
11:31 make that decision with those two modes but if that leave one switch will make a
11:37 decision I will go through S1 or S2 or S3 they need to be aware of each other
11:43 of each other is there some kind of a stacking mechanism between those switches or not a great question and
11:49 that's the next technique that is GB that actually takes a global view in this one so I'm just going to uh say so
11:56 this one is effective yes you are right there these are based on local decisions local link quality and still you can
12:02 still send some extra traffic to a spine and that the GB will will solve that
12:07 problem but this well we're still on the local Brian Martin here signal 65 correct u for the flow lit mode u those
12:14 periods of inactivity you mentioned 16 20 micros is that tunable is that you're
12:20 we can set that so the lowest you can go is 16 microconds and then anything up to
12:25 yeah you can do that um so yeah so this basically solves uh
12:30 if you see this picture this solves this problem right the local you going to fairly distribute um uh traffic over all
12:38 the the leaves and you will not you'll avoid getting overloading a single uh because you're now tracking each link
12:45 right but the other problem is still there and I'll come to uh your question what does ECMP stand for equal cost
12:52 multipath so okay so because these are symmetric lowark architectures in data
12:57 center so you you know a routing protocol will uh build all the paths that are equal cost and the leaf will
13:03 pick one of them based on a load bal balancing that you choose Okay and since
13:09 we're right here what is EXIA oh EXIA is a traffic generator so
13:15 keyite okay oh so um yeah so here what we did is we uh in the lab uh that we
13:22 have here with with the uh Nvidia GPUs um we s we put these three uh uh
13:29 techniques to to uh test right so the first one is static ECMP that's the hashbased ACMP DLB flowlet mode and the
13:36 DB per packet mode that's the packet spring and we used a ML common
13:42 standardized benchmark um DLRM for this uh test and what we found is you know
13:47 the static ECMP duty rates as and and sorry one more thing is we used the Xia
13:52 traffic generator to introduce congestion so that we can see the performance under congestion right so as
13:58 we increase the load on the traffic generator started introducing more and more congestion you see that the static
14:04 ECMP starts to deteriorate uh DLB was very deterministic highly deterministic
14:10 and it actually did pretty well as the as there more congestion was introduced
14:15 uh best was still packet spraying as you can see from that um you know the the 37.5% number uh but it was only by a
14:24 margin of 08% right so the flowlet really did well without you needing any
14:30 special nicks to handle or you know expensive nicks to handle this so uh
14:35 really there is not that much of a uh ROI on on that right and if you see
14:40 pictorially this is a graph that shows you what was the link how did how much
14:46 traffic was going on all the paths um between leaf and spines right so as you
14:51 can see static ECMP it was a random distribution some links were were highly utilized some were not whereas in DB
14:58 flowlet you see all the links are fairly utilized um and that's that explains the
15:03 performance predictability and the packet spray also looked exactly like it's indistinguishable that's why I don't
15:09 show you but that's how it looked like um and in terms of variability so the
15:15 number of times so this is a graph on we did three consecutive tests and this is a nickel test which is a standard Nvidia
15:23 uh open source tool and you can see the variability in performance of static
15:28 ECMP which is basically lottery based you're pinning you know you're picking a path One time it got really lucky and
15:35 had really peak performance but the next time it was 196 and third time it was
15:40 around 263 right so and this is in a controlled environment whereas in in real uh clusters where the multi-tenant
15:47 traffic is hitting this variability can really hurt right uh whereas the DLB
15:52 really reduce that variability band to a very narrow one and you have you know 373 to 353 which is uh which is really
16:01 good Um now coming to the global load
16:07 balancing so the second problem is still based on local decisions DLB or these leaves can still send some traffic where
16:14 you know even though you have built an equal uh one is to1 capacity because of these local decisions may skew some
16:22 traffic or you know uh create imbalances by sending uh traffic to a spine um and
16:29 in this case what we do is so for the DLB uh the ASIC already calculates all of its local link quality in GB what it
16:36 does is it actually sends it one half of uh upstream or in this case the spines
16:43 are going to send that link quality data that they're measuring locally to these leaves right and now these leaves
16:50 because leaf is the first leaf is the most effective point of uh you know um of uh uh where you can take a good load
16:57 balancing decision in clo the at the top of the tree you pretty much have um only
17:03 one path uh down right so that uh the now these leaves are armed with that information so what they do in in the in
17:10 the example that you brought up so let's say GPU 2 is going to talk to GPU 6 what
17:16 the leaf does is first it refers its local link quality and says okay one of the links to spine one is already a lot
17:22 of traffic is going there i will avoid that but I have two two paths now right
17:27 uh to spine two and spine 3 and if it was only DLB it would have picked one of
17:33 them right and in this case now it is armed with this information that spine two told it like hey I one of my links
17:40 is congested so in this case the leaf one is going to say okay I'm not going
17:46 to send traffic that way because I have a clean path all through via spine 3 so let me load balance this flow new flow
17:53 onto that path right and two things need to happen here one is an async to
18:00 realtime update that's updated uh but one more thing we have done is we have an IETF draft uh which we have published
18:07 and you know enhancing BGP where now we are tracking next next hub right so
18:13 these leaves and that's done like in the control plane it doesn't have to be in the in the runtime so each leaf knows
18:20 like for every destination leaf which flows may take which path because let's
18:25 say when the real time update comes from S2 S2 says hey my uh my link to S2 and
18:31 to L3 three that one in the red is congested or is is is highly utilized
18:37 then it needs to determine which flows may take that link right because it will
18:42 it still needs to send a all the traffic to other 62 ports on that spine 2 um
18:48 still to spine 2 right so that's how we just uh we just determined that by the BGP's next next hop tracking on the leaf
18:55 and then when the update comes we just pull those uh routes out and so the for the temporarily time being the traffic
19:02 will not be sent to that spine and when we get the next update and if that link is fine we just restore them and then
19:08 you know load balancing is restored yes so so I think back uh to the to the earlier question about what's handling
19:13 state I think you just answered that right we're moving that into the BGP control plane and saying hey BGP is
19:19 going to advertise keep up with what's available what's not available uh any
19:24 potential performance hits from that perspective i mean that it sounds like that might be a lot of BGP updates
19:29 unless we're looking at very similar traffic types in this cluster so BGP uh
19:34 we relying on BGP to learn the paths and also we have done this enhancement to know hey not just next top I need to now
19:42 know hey what next next top so which links so that's done maybe when even training has not started so you build
19:49 this and that's fine in the runtime when traffic is running there is a as to GB
19:55 update when that comes in I just refer to this table and say hey spine 2 has reported me this link is on what did BGP
20:03 tell me which destination may take that link on that spine we just take that out and put that so BGP really is not in the
20:11 runtime so there is no reliance on BGP update to this there's a GB update that's mapped to already built topology
20:19 information that BGP was used for got so this is like as Proful said uh
20:25 like a Google maps right like so it gives you end to end visibility not just like hey what does my uh freeway look
20:31 like right now but what's the next connecting freeways so Google Maps is a good analogy there uh cuz the color can
20:38 go from blue to yellow to red to black uh I see low and high there what's the
20:43 granularity on those paths great question yeah so again so here just to explain I had three three um three
20:50 levels it's actually eight levels so eight bands of quality are there 0 to 7
20:56 and that's what is used for DB decisions as well as um JB Thank you
21:04 so now then uh you know so these two are quite effective at actually solving a
21:09 lot of congestion and as you can see they're uh dynamic because they're reacting to um wherever congestion is
21:17 created in spite of you know you fairly distributing the flows and then we at Juniper we try to challenge ourselves
21:23 like saying hey is there is there a simple and better way to actually avoid
21:28 congestion right so this RDMA where load balancing um I will um I'll just take a
21:35 moment to describe it now whenever um the uh these uh the training is
21:42 occurring at the fundamental level whenever a GPU needs to write um something or synchronize its gradients
21:48 or whatever it's doing or RDMA to another GPU's memory at the fundamental
21:53 level or lower level what happens is so these are orchestrated by a middleware called nickel uh which is communications
22:00 library from Nvidia and it sets up like these uh I mean the analogy could be
22:06 like these sockets in the TCP world right but these are created by a middleware and then reused over time so
22:13 what happens is there is a memory region associated on let's say the left side is the sender GPU and then there is a
22:20 receiver GPU so if it has to write 2 GB of uh data over this RDMA and Ethernet
22:26 and over the network to this at the RDMA layer there is a Q pair which is mapped
22:31 to a memory region on both ends and then this Q pair is um then used uh over UDP
22:38 and IP and Ethernet and send over the the network right yeah yeah just to for
22:43 listeners RDMA what does it stand for uh remote direct memory
22:51 accessirect remote access so DMA is like whenever you you know whenever your CPU
22:57 fetches from your local laptop's memory or RAM uh you know and then remote is like when it can fetch or do operations
23:05 or remotely on on another uh on another CPU or G GPU's uh RAM so that's what it
23:11 is so remote direct memory access thank you and so
23:17 um so so this is like you know so you have a giant flow of 400 gig if you use a single Q pair on both ends so one of
23:24 the techniques um is like hey can I extract more subflows so that you know I
23:29 can spray them I can create more subflows so that the fabric can usually load balance them across all the
23:34 available paths so what uh this does is hey can we do four q pairs I mean q pair
23:42 is like you know both ends in this case what what the nick that's anchoring the rdma does is like okay I'm going we have
23:48 to write that same 2 gabyte I'm going to break it into 500 megabytes four regions
23:54 on both ends use four q pairs and transmit like 100 gig four flows right
24:00 and uh this is not new this is when this is enabled usually what happens is each
24:06 q pair uses a random UDP unique source port so that the switches when this
24:11 traffic hits the switch it can hash it can catch that okay there are four flows now and it can then distribute these
24:18 flows right correct and because it's based on random so it is like the you know you you have to hash and there's no
24:25 determinism right what we what we did is very simple idea we added
24:30 determinism by we said hey can we instead of using a random port uh which
24:36 has been done for for 10 years can we assign an IP address to each flow and
24:43 then if we do that the beauty of that is we create this to a instead of random and hashing and all those things a
24:49 deterministic routing problem and you can now do a nice traffic engineering and pretty much carve out a lane for it
24:56 throughout the fabric because the capacity exists it's just that the load balancing which usually hashes on on a
25:04 source port uh takes this decision so in essence what you're doing there is
25:09 you're you're taking away uh using just a random number to try to load balance
25:15 correct and instead doing the work to actually map all those flows exactly right and still using routing protocols
25:21 Ethernets distributed routing protocols of your choice but BGP preferably uh and what what that does and uh is so these
25:29 same four flows think of it as like you know so now you have a deterministic flow with its own source and destination
25:35 IP and we have a pre-card path so let's say you have a the first uh flow is from
25:41 a subnet A the second is B C and D kind of thing and then you can now use traffic engineering to pre-carve uh this
25:48 path like saying that hey all the first flows now deterministically can take the
25:54 first spine or the a preferred path so it's you're pretty much um taking the
26:00 randomness away you say hey I because the capacity exists you have build you spend money and having this one is to
26:06 one hour subscription it's just the load balancing was not may get you in tricky situations at times it'll work most of
26:12 the time in this case it is predictable deterministic uh thing so if all the flows blow up we disagregate these flows
26:20 into so that there is a important concept n so we break these flows at as many paths you have from the leaf so in
26:26 this case you have four paths through four spines we'll break these subflows into four right and uh if all the flows
26:34 blow up in this case let's say there are eight nicks and you know so each one will be a 100 gig flow now and they will
26:41 because there are eight GPUs you will have 8 by 100 gig which is that link is 8 by 100 gig so there won't be
26:46 congestion there won't be any out of order packets because they're not going to take any other path it's a it's a
26:52 reserved lane uh for each subflow Right very simple idea uh but very very
26:58 effective right so uh sorry question um now you are assuming that uh all those
27:05 GPUs require the full bandwidth yes is that always the case uh it's not but you
27:12 have to build for that case and they are built for this so you have for example like let me show you the next picture
27:18 right um usually these are like um um 64
27:23 by 800 gig um uh switch so what we do is one is to one um what you do is you
27:29 because these nicks are 400 so you split the 8 uh uh 800 gig um uh into 2x400 you
27:36 attach 64 GPUs and then you have to budget that in case all of that traffic
27:41 comes to the leaf you will have 32x 800 gig so that's what I mean one is to one or subscription meaning whatever uh
27:49 ports you reserve for the GPU facing or the host facing you have to have enough exact capacity towards the spine to
27:56 handle if all GPUs are sending full line rate so in this case what we do is what
28:02 as I show you there are if there are is a scaled 4,000 GPU uh topology if you
28:07 have 32 paths in this case because 32x 800 gig is equal to 64 by 800 here you
28:14 divide these uh you break your n becomes 32 and you will do 32 q pairs so that if
28:20 all of them all the the GPUs here uh uh start sending traffic it will fit nicely
28:27 in a predeterministic f fashion and here you eliminate uh load balancing
28:34 this is pure routing uh because this fabric is built on you know BGP and when
28:39 the flows come up with just a uh lookup and there's a preferred path for each of the uh you know colors and that's how
28:46 this works now the way routing works is like for each of these colors shown here we will
28:53 have a higher preferred route um to a spine and the second color will have the blue spine and so on but we will still
29:00 advertise a lower preferred route through the backup for just in case that link fails right because failures are a
29:07 reality so this is how we will still advertise ECMP paths lower preferred or backup paths but a preferred high high
29:14 path so when when everything is in steady state you have that determinism and let's
29:19 say let's say a link or a switch fails in that case what happens is for this um
29:27 for this flow which was preferred path was that spine all the backup paths are activated and it will do dynamic DLB and
29:34 GB across all the other paths right for the time being and as soon as that link
29:40 gets restored or the switch gets restored it will immediately snap app back to um the deterministic forwarding
29:48 so I just noticed you switched from earlier in the slide deck you were using rail or rail optimized network topology
29:55 correct and with these optimizations you've dropped back to a standard leaf and spine okay hold your thought yes
30:02 great point though you're that means I'm uh able to explain this well so you know that's a that's a great point yeah I
30:09 have it covered so I'll go over it um so now if you see the variability right
30:15 like I flashed this like so again uh quick rehash ECMP gets lucky sometimes
30:20 over and this is like in a controller environment three consecutive runs DLB improved it considerably reduced that uh
30:27 unpredictability to a narrow band but look at this so uh this RDMA aware load
30:33 balancing what we call RLB is consistently hitting the 373 highest performance mark all the time cuz as you
30:40 see there the in the design there is nothing in steady state um you know it always performs no
30:46 conflict there is no um load balancing uh introduced um randomness anymore
30:51 right so that is a so it'll keep the network running at peak performance uh
30:57 by by this design all the time which is very desirable and again here I'm just showing um you know uh the DLB and RLB
31:06 some other metrics that we measured so as you can see in the DLB case yes uh
31:12 all the links so again these are all the the the traffic on all the links between leaf and spine and as you can see and we
31:19 we bombard with all our uh GPUs the traffic using nickel test and what we saw is with the u with the DLB yes the
31:27 traffic is fairly distributed over across links but still at some point it starts um causing micro uh congestions
31:34 right uh but in this case there is no congestion because you know there is a reserved path and it's it's just a
31:40 straight peak and a flat line up there uh during multiple runs we never saw any congestion uh metrics so ECN and PFCs
31:47 are DCQCN is primarily uh congestion avoidance mechanism in this u Ethernet
31:52 and we didn't see any of those triggered and no out of order packets because of course uh it's designed to follow a
31:59 single path uh through the fabric anyways uh whereas in the case of uh uh the other one and this is for rail
32:05 optimized and I'm going to come to the non-reail um now this is what the point you were
32:12 trying to say and uh so in 2018 19 when Nvidia started
32:18 recommending these rail optimized designs it was like hey uh traditional ethern uh or load balancing techniques
32:25 are not not enough so um you know we will connect them in such a way that you
32:31 know you have rail optimized uh designs and that is true because you know it
32:37 takes off some of the the load balancing um requirement from the leaves then we
32:43 said hey if we are achieving this kind of a performance in rail optimize is this good enough to now go back to top
32:50 of rack switch where you know you have all these connections uh in a in a top
32:55 of rack switch that allows you to use now copper right DAC cables um and DAC
33:01 cables are you know way cheaper uh less expensive they consume very low power uh
33:08 they're more reliable um compared to optics and you know The traditional
33:13 sense was hey performance you will not be able to get because you need to connect rail so you have to run the longer cable so we said okay let's put
33:19 this to test right and what we found is almost this brings not even non-reil uh
33:24 which is basically the top of the rack it brings brought it to almost uh peak performance uh because you know we saw I
33:31 mean uh this is this is actual lab results from from multiple runs so really um and this is again the similar
33:40 graph there was still no congestion uh no out of orders delivered uh for for
33:45 the non-rail um whereas DLB was still had it in that explains it right so so
33:51 really um if you I summarize the benefit of uh this new very simple idea uses all
33:57 the components of what Ethernet's routing protocols and you know just by um assigning determinism to these flows
34:04 and converting it into a routing column you have consistent high performance like predictable in steady state uh you
34:11 have in order delivery because in steady state they you know they they will all follow the the consecutive packets will
34:17 follow the same path and this is done without the need for any expensive hardware like um you know extra nakes or
34:23 super nakes or you know debuffer switches and things like that and this also delivers non-rail performance which
34:30 is highly desirable because of uh you know um the properties
34:35 oh for those for those of you that don't know the difference between rail and non-rail uh in a rail environment any
34:43 communication from a GPU on a different rail has to travel through the PCI
34:48 connection to the other GPU and then across the network so one extra step for
34:54 rail config yeah so actually that's uh that is it yeah sure so any questions
35:02 one more yeah sure go ahead please um when you look at scaling up when we get into very large clusters um do you see
35:10 the le the regular claus um scaling up that high what do the topology start to
35:16 look like or the trade-offs start to look like between rail and class so in
35:21 the rail one uh rail topology again uh and that'll apply to non-reail as well as you go like through the five stage
35:28 usually we start seeing um over subscription um 7 is to1 5 is to1 that
35:34 kind of because the traffic that's traversing through across that is is
35:39 becomes lower and that's because also um you know a lot of this orchestr
35:44 orchestrators have a locality uh property where they will try like hey you need GPUs of 100 GPUs or you know
35:51 thousand GPUs they will try to orchestrate the workload in a local area where you know you don't have to
35:58 traverse that high you know they're all in a in a cl topology where you know don't have to take more hops so that's
36:04 why you can go over subscription and because um in the case of RLB you um
36:12 that over subscription we're using uh you know BGP communities and stuff so you can still architect and factor any
36:18 over subscription on that layer where you will start assigning multiple spines um you know to handle the same color